字符串
在其他语言中,字符串往往是送分题,因为实在是太简单了,例如 "hello, world" 就是字符串章节的几乎全部内容了,但是如果你带着同样的想法来学 Rust,我保证,绝对会栽跟头,因此这一章大家一定要重视,仔细阅读。
首先来看段很简单的代码:
rust
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}greet 函数接受一个字符串类型的 name 参数,然后打印到终端控制台中,非常好理解,你们猜猜,这段代码能否通过编译?
conole
error[E0308]: mismatched types
--> src/main.rs:3:11
|
3 | greet(my_name);
| ^^^^^^^
| |
| expected struct `std::string::String`, found `&str`
| help: try using a conversion method: `my_name.to_string()`
error: aborting due to previous error果然报错了,编译器提示 greet 函数需要一个 String 类型的字符串,却传入了一个 &str 类型的字符串,相信读者心中现在一定有几头草泥马呼啸而过,怎么字符串也能整出这么多花活?
在讲解字符串之前,先来看看什么是切片?
切片(slice)
切片并不是 Rust 独有的概念,在 Go 语言中就非常流行,它允许你引用集合中部分连续的元素序列,而不是引用整个集合。
对于字符串而言,切片就是对 String 类型中某一部分的引用,它看起来像这样:
rust
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];hello 没有引用整个 String s,而是引用了 s 的一部分内容,通过 [0..5] 的方式来指定。
这就是创建切片的语法,使用方括号包括的一个序列:[开始索引..终止索引],其中开始索引是切片中第一个元素的索引位置,而终止索引是最后一个元素后面的索引位置,也就是这是一个 右半开区间。在切片数据结构内部会保存开始的位置和切片的长度,其中长度是通过 终止索引 - 开始索引 的方式计算得来的。
对于 let world = &s[6..11]; 来说,world 是一个切片,该切片的指针指向 s 的第 7 个字节(索引从 0 开始, 6 是第 7 个字节),且该切片的长度是 5 个字节。
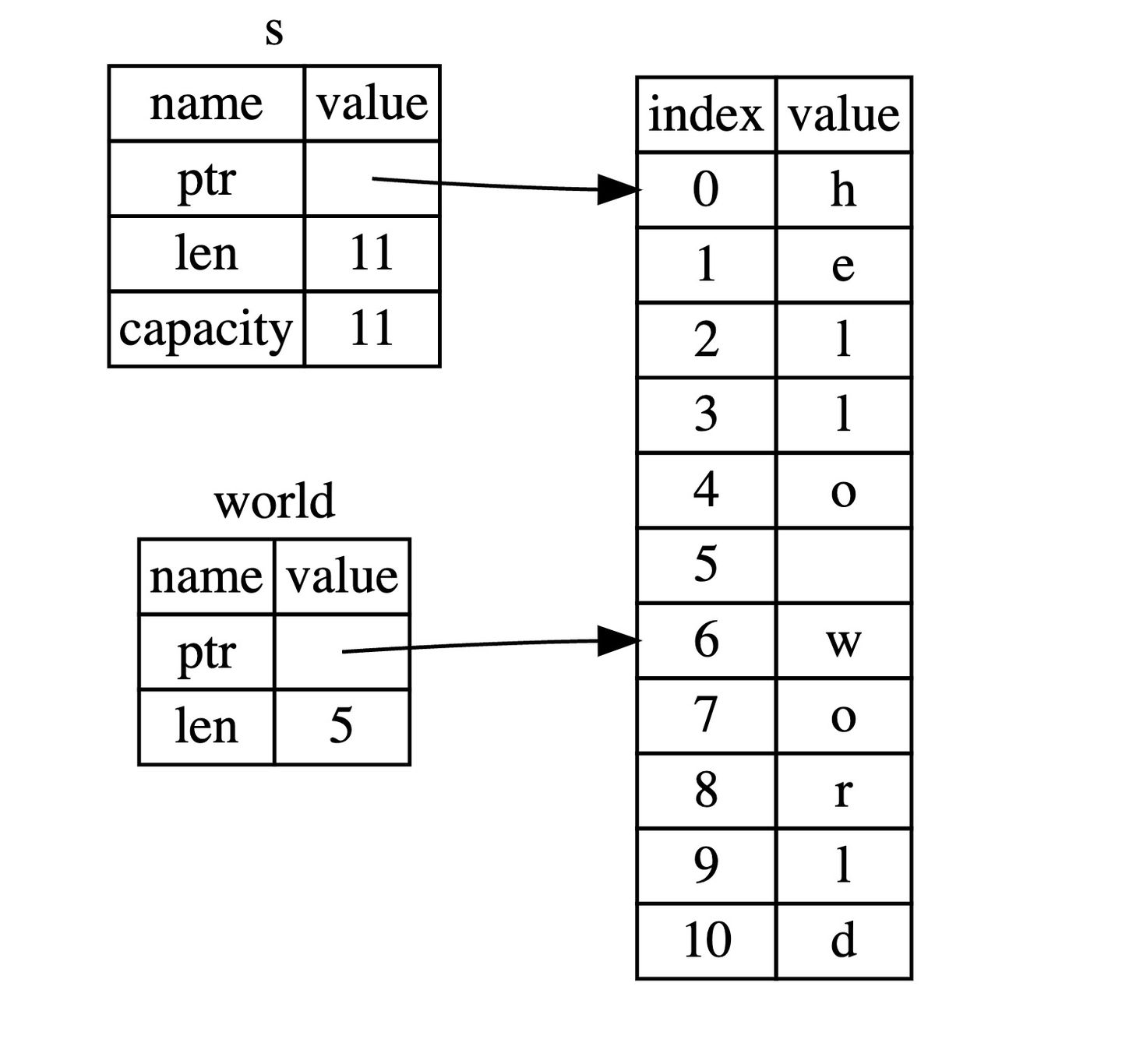
在使用 Rust 的 .. range 序列语法时,如果你想从索引 0 开始,可以使用如下的方式,这两个是等效的:
rust
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];同样的,如果你的切片想要包含 String 的最后一个字节,则可以这样使用:
rust
let s = String::from("hello");
let len = s.len();
let slice = &s[4..len];
let slice = &s[4..];你也可以截取完整的 String 切片:
rust
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
rustlet s = "中国人"; let a = &s[0..2]; println!("{}",a);因为我们只取
s字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连中字都取不完整,此时程序会直接崩溃退出,如果改成&s[0..3],则可以正常通过编译。 因此,当你需要对字符串做切片索引操作时,需要格外小心这一点, 关于该如何操作 UTF-8 字符串,参见这里。
字符串切片的类型标识是 &str,因此我们可以这样声明一个函数,输入 String 类型,返回它的切片: fn first_word(s: &String) -> &str 。
有了切片就可以写出这样的代码:
rust
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
fn first_word(s: &String) -> &str {
&s[..1]
}编译器报错如下:
console
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here回忆一下借用的规则:当我们已经有了可变借用时,就无法再拥有不可变的借用。因为 clear 需要清空改变 String,因此它需要一个可变借用;而之后的 println! 又使用了不可变借用,也就是在 s.clear() 处可变借用与不可变借用试图同时生效,因此编译无法通过。
从上述代码可以看出,Rust 不仅让我们的 API 更加容易使用,而且也在编译期就消除了大量错误!
其它切片
因为切片是对集合的部分引用,因此不仅仅字符串有切片,其它集合类型也有,例如数组:
rust
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);该数组切片的类型是 &[i32],数组切片和字符串切片的工作方式是一样的,例如持有一个引用指向原始数组的某个元素和长度。
字符串字面量是切片
之前提到过字符串字面量,但是没有提到它的类型:
rust
let s = "Hello, world!";实际上,s 的类型是 &str,因此你也可以这样声明:
rust
let s: &str = "Hello, world!";该切片指向了程序可执行文件中的某个点,这也是为什么字符串字面量是不可变的,因为 &str 是一个不可变引用。
了解完切片,可以进入本节的正题了。
什么是字符串?
顾名思义,字符串是由字符组成的连续集合,但是在上一节中我们提到过,Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4),这样有助于大幅降低字符串所占用的内存空间。
Rust 在语言级别,只有一种字符串类型: str,它通常是以引用类型出现 &str,也就是上文提到的字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型。
str 类型是硬编码进可执行文件,也无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
除了 String 类型的字符串,Rust 的标准库还提供了其他类型的字符串,例如 OsString, OsStr, CsString 和 CsStr 等,注意到这些名字都以 String 或者 Str 结尾了吗?它们分别对应的是具有所有权和被借用的变量。
String 与 &str 的转换
在之前的代码中,已经见到好几种从 &str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那么如何将 String 类型转为 &str 类型呢?答案很简单,取引用即可:
rust
fn main() {
let s = String::from("hello,world!");
say_hello(&s);
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}实际上这种灵活用法是因为 deref 隐式强制转换,具体我们会在其他章节详细讲解。
字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错:
rust
let s1 = String::from("hello");
let h = s1[0];该代码会产生如下错误:
console
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`字符串切片
前文提到过,字符串切片是非常危险的操作,因为切片的索引是通过字节来进行,但是字符串又是 UTF-8 编码,因此你无法保证索引的字节刚好落在字符的边界上,例如:
rust
let hello = "中国人";
let s = &hello[0..2];运行上面的程序,会直接造成崩溃:
console
thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '中' (bytes 0..3) of `中国人`', src/main.rs:4:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace这里提示的很清楚,我们索引的字节落在了 中 字符的内部,这种返回没有任何意义。
因此在通过索引区间来访问字符串时,需要格外的小心,一不注意,就会导致你程序的崩溃!
操作字符串
由于 String 是可变字符串,下面介绍 Rust 字符串的修改,添加,删除等常用方法:
追加 (Push)
在字符串尾部可以使用 push() 方法追加字符 char,也可以使用 push_str() 方法追加字符串字面量。这两个方法都是在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
rust
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("追加字符串 push_str() -> {}", s);
s.push('!');
println!("追加字符 push() -> {}", s);
}代码运行结果:
console
追加字符串 push_str() -> Hello rust
追加字符 push() -> Hello rust!插入 (Insert)
可以使用 insert() 方法插入单个字符 char,也可以使用 insert_str() 方法插入字符串字面量,与 push() 方法不同,这俩方法需要传入两个参数,第一个参数是字符(串)插入位置的索引,第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。由于字符串插入操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
rust
fn main() {
let mut s = String::from("Hello rust!");
s.insert(5, ',');
println!("插入字符 insert() -> {}", s);
s.insert_str(6, " I like");
println!("插入字符串 insert_str() -> {}", s);
}代码运行结果:
console
插入字符 insert() -> Hello, rust!
插入字符串 insert_str() -> Hello, I like rust!替换 (Replace)
如果想要把字符串中的某个字符串替换成其它的字符串,那可以使用 replace() 方法。与替换有关的方法有三个。
1、replace
该方法可适用于 String 和 &str 类型。replace() 方法接收两个参数,第一个参数是要被替换的字符串,第二个参数是新的字符串。该方法会替换所有匹配到的字符串。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
rust
fn main() {
let string_replace = String::from("I like rust. Learning rust is my favorite!");
let new_string_replace = string_replace.replace("rust", "RUST");
dbg!(new_string_replace);
}代码运行结果:
console
new_string_replace = "I like RUST. Learning RUST is my favorite!"2、replacen
该方法可适用于 String 和 &str 类型。replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
rust
fn main() {
let string_replace = "I like rust. Learning rust is my favorite!";
let new_string_replacen = string_replace.replacen("rust", "RUST", 1);
dbg!(new_string_replacen);
}代码运行结果:
console
new_string_replacen = "I like RUST. Learning rust is my favorite!"3、replace_range
该方法仅适用于 String 类型。replace_range 接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
示例代码如下:
rust
fn main() {
let mut string_replace_range = String::from("I like rust!");
string_replace_range.replace_range(7..8, "R");
dbg!(string_replace_range);
}代码运行结果:
console
string_replace_range = "I like Rust!"删除 (Delete)
与字符串删除相关的方法有 4 个,它们分别是 pop(),remove(),truncate(),clear()。这四个方法仅适用于 String 类型。
1、 pop —— 删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None。 示例代码如下:
rust
fn main() {
let mut string_pop = String::from("rust pop 中文!");
let p1 = string_pop.pop();
let p2 = string_pop.pop();
dbg!(p1);
dbg!(p2);
dbg!(string_pop);
}代码运行结果:
console
p1 = Some(
'!',
)
p2 = Some(
'文',
)
string_pop = "rust pop 中"2、 remove —— 删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。remove() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
rust
fn main() {
let mut string_remove = String::from("测试remove方法");
println!(
"string_remove 占 {} 个字节",
std::mem::size_of_val(string_remove.as_str())
);
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
dbg!(string_remove);
}代码运行结果:
console
string_remove 占 18 个字节
string_remove = "试remove方法"3、truncate —— 删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法 truncate() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
rust
fn main() {
let mut string_truncate = String::from("测试truncate");
string_truncate.truncate(3);
dbg!(string_truncate);
}代码运行结果:
console
string_truncate = "测"4、clear —— 清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于 truncate() 方法参数为 0 的时候。
示例代码如下:
rust
fn main() {
let mut string_clear = String::from("string clear");
string_clear.clear();
dbg!(string_clear);
}代码运行结果:
console
string_clear = ""连接 (Concatenate)
1、使用 + 或者 += 连接字符串
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的 add() 方法,这里 add() 方法的第二个参数是一个引用的类型。因此我们在使用 + 时, 必须传递切片引用类型。不能直接传递 String 类型。+ 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰。
示例代码如下:
rust
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
println!("连接字符串 + -> {}", result);
}代码运行结果:
console
连接字符串 + -> hello rust!!!!add() 方法的定义:
rust
fn add(self, s: &str) -> String因为该方法涉及到更复杂的特征功能,因此我们这里简单说明下:
rust
fn main() {
let s1 = String::from("hello,");
let s2 = String::from("world!");
// 在下句中,s1的所有权被转移走了,因此后面不能再使用s1
let s3 = s1 + &s2;
assert_eq!(s3,"hello,world!");
// 下面的语句如果去掉注释,就会报错
// println!("{}",s1);
}self 是 String 类型的字符串 s1,该函数说明,只能将 &str 类型的字符串切片添加到 String 类型的 s1 上,然后返回一个新的 String 类型,所以 let s3 = s1 + &s2; 就很好解释了,将 String 类型的 s1 与 &str 类型的 s2 进行相加,最终得到 String 类型的 s3。
由此可推,以下代码也是合法的:
rust
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
// String = String + &str + &str + &str + &str
let s = s1 + "-" + &s2 + "-" + &s3;String + &str返回一个 String,然后再继续跟一个 &str 进行 + 操作,返回一个 String 类型,不断循环,最终生成一个 s,也是 String 类型。
s1 这个变量通过调用 add() 方法后,所有权被转移到 add() 方法里面, add() 方法调用后就被释放了,同时 s1 也被释放了。再使用 s1 就会发生错误。这里涉及到所有权转移(Move)的相关知识。
2、使用 format! 连接字符串
format! 这种方式适用于 String 和 &str 。format! 的用法与 print! 的用法类似,详见格式化输出。
示例代码如下:
rust
fn main() {
let s1 = "hello";
let s2 = String::from("rust");
let s = format!("{} {}!", s1, s2);
println!("{}", s);
}代码运行结果:
console
hello rust!元组
元组是由多种类型组合到一起形成的,因此它是复合类型,元组的长度是固定的,元组中元素的顺序也是固定的。
可以通过以下语法创建一个元组:
rust
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}变量 tup 被绑定了一个元组值 (500, 6.4, 1),该元组的类型是 (i32, f64, u8),看到没?元组是用括号将多个类型组合到一起,简单吧?
可以使用模式匹配或者 . 操作符来获取元组中的值。
用模式匹配解构元组
rust
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {}", y);
}上述代码首先创建一个元组,然后将其绑定到 tup 上,接着使用 let (x, y, z) = tup; 来完成一次模式匹配,因为元组是 (n1, n2, n3) 形式的,因此我们用一模一样的 (x, y, z) 形式来进行匹配,元组中对应的值会绑定到变量 x, y, z上。这就是解构:用同样的形式把一个复杂对象中的值匹配出来。
用 . 来访问元组
模式匹配可以让我们一次性把元组中的值全部或者部分获取出来,如果只想要访问某个特定元素,那模式匹配就略显繁琐,对此,Rust 提供了 . 的访问方式:
rust
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}和其它语言的数组、字符串一样,元组的索引从 0 开始。
元组的使用示例
元组在函数返回值场景很常用,例如下面的代码,可以使用元组返回多个值:
rust
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的长度
(s, length)
}calculate_length 函数接收 s1 字符串的所有权,然后计算字符串的长度,接着把字符串所有权和字符串长度再返回给 s2 和 len 变量。
结构体
结构体由其它数据类型组合而来。 其它语言也有类似的数据结构,不过可能有不同的名称,例如 object、 record 等。
结构体跟之前讲过的元组有些相像:都是由多种类型组合而成。但是与元组不同的是,结构体可以为内部的每个字段起一个富有含义的名称。因此结构体更加灵活更加强大,你无需依赖这些字段的顺序来访问和解析它们。
结构体语法
天下无敌的剑士往往也因为他有一柄无双之剑,既然结构体这么强大,那么我们就需要给它配套一套强大的语法,让用户能更好的驾驭。
定义结构体
一个结构体由几部分组成:
- 通过关键字
struct定义 - 一个清晰明确的结构体
名称 - 几个有名字的结构体
字段
例如, 以下结构体定义了某网站的用户:
rust
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}该结构体名称是 User,拥有 4 个字段,且每个字段都有对应的字段名及类型声明,例如 username 代表了用户名,是一个可变的 String 类型。
创建结构体实例
为了使用上述结构体,我们需要创建 User 结构体的实例:
rust
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};有几点值得注意:
- 初始化实例时,每个字段都需要进行初始化
- 初始化时的字段顺序不需要和结构体定义时的顺序一致
访问结构体字段
通过 . 操作符即可访问结构体实例内部的字段值,也可以修改它们:
rust
let mut user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");需要注意的是,必须要将结构体实例声明为可变的,才能修改其中的字段,Rust 不支持将某个结构体某个字段标记为可变。
简化结构体创建
下面的函数类似一个构建函数,返回了 User 结构体的实例:
rust
fn build_user(email: String, username: String) -> User {
User {
email: email,
username: username,
active: true,
sign_in_count: 1,
}
}它接收两个字符串参数: email 和 username,然后使用它们来创建一个 User 结构体,并且返回。可以注意到这两行: email: email 和 username: username,非常的扎眼,因为实在有些啰嗦,如果你从 TypeScript 过来,肯定会鄙视 Rust 一番,不过好在,它也不是无可救药:
rust
fn build_user(email: String, username: String) -> User {
User {
email,
username,
active: true,
sign_in_count: 1,
}
}如上所示,当函数参数和结构体字段同名时,可以直接使用缩略的方式进行初始化,跟 TypeScript 中一模一样。
结构体更新语法
在实际场景中,有一种情况很常见:根据已有的结构体实例,创建新的结构体实例,例如根据已有的 user1 实例来构建 user2:
rust
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};Rust 为我们提供了 结构体更新语法:
rust
let user2 = User {
email: String::from("another@example.com"),
..user1
};因为 user2 仅仅在 email 上与 user1 不同,因此我们只需要对 email 进行赋值,剩下的通过结构体更新语法 ..user1 即可完成。
.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是 ..user1 必须在结构体的尾部使用。
rust
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
println!("{}", user1.active);
// 下面这行会报错
println!("{:?}", user1);数组
在日常开发中,使用最广的数据结构之一就是数组,在 Rust 中,最常用的数组有两种,第一种是速度很快但是长度固定的 array,第二种是可动态增长的但是有性能损耗的 Vector,在本书中,我们称 array 为数组,Vector 为动态数组。
不知道你们发现没,这两个数组的关系跟 &str 与 String 的关系很像,前者是长度固定的字符串切片,后者是可动态增长的字符串。其实,在 Rust 中无论是 String 还是 Vector,它们都是 Rust 的高级类型:集合类型,在后面章节会有详细介绍。
对于本节,我们的重点还是放在数组 array 上。数组的具体定义很简单:将多个类型相同的元素依次组合在一起,就是一个数组。结合上面的内容,可以得出数组的三要素:
- 长度固定
- 元素必须有相同的类型
- 依次线性排列
这里再啰嗦一句,我们这里说的数组是 Rust 的基本类型,是固定长度的,这点与其他编程语言不同,其它编程语言的数组往往是可变长度的,与 Rust 中的动态数组 Vector 类似,希望读者大大牢记此点。
创建数组
在 Rust 中,数组是这样定义的:
rust
fn main() {
let a = [1, 2, 3, 4, 5];
}数组语法跟 JavaScript 很像,也跟大多数编程语言很像。由于它的元素类型大小固定,且长度也是固定,因此数组 array 是存储在栈上,性能也会非常优秀。与此对应,动态数组 Vector 是存储在堆上,因此长度可以动态改变。当你不确定是使用数组还是动态数组时,那就应该使用后者,具体见动态数组 Vector。
举个例子,在需要知道一年中各个月份名称的程序中,你很可能希望使用的是数组而不是动态数组。因为月份是固定的,它总是只包含 12 个元素:
rust
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];在一些时候,还需要为数组声明类型,如下所示:
rust
let a: [i32; 5] = [1, 2, 3, 4, 5];这里,数组类型是通过方括号语法声明,i32 是元素类型,分号后面的数字 5 是数组长度,数组类型也从侧面说明了数组的元素类型要统一,长度要固定。
还可以使用下面的语法初始化一个某个值重复出现 N 次的数组:
rust
let a = [3; 5];a 数组包含 5 个元素,这些元素的初始化值为 3,聪明的读者已经发现,这种语法跟数组类型的声明语法其实是保持一致的:[3; 5] 和 [类型; 长度]。
在元素重复的场景,这种写法要简单的多,否则你就得疯狂敲击键盘:let a = [3, 3, 3, 3, 3];,不过老板可能很喜欢你的这种疯狂编程的状态。
访问数组元素
因为数组是连续存放元素的,因此可以通过索引的方式来访问存放其中的元素:
rust
fn main() {
let a = [9, 8, 7, 6, 5];
let first = a[0]; // 获取a数组第一个元素
let second = a[1]; // 获取第二个元素
}与许多语言类似,数组的索引下标是从 0 开始的。此处,first 获取到的值是 9,second 是 8。
越界访问
如果使用超出数组范围的索引访问数组元素,会怎么样?下面是一个接收用户的控制台输入,然后将其作为索引访问数组元素的例子:
rust
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
// 读取控制台的输出
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!(
"The value of the element at index {} is: {}",
index, element
);
}使用 cargo run 来运行代码,因为数组只有 5 个元素,如果我们试图输入 5 去访问第 6 个元素,则会访问到不存在的数组元素,最终程序会崩溃退出:
console
Please enter an array index.
5
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 5', src/main.rs:19:19
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace这就是数组访问越界,访问了数组中不存在的元素,导致 Rust 运行时错误。程序因此退出并显示错误消息,未执行最后的 println! 语句。
当你尝试使用索引访问元素时,Rust 将检查你指定的索引是否小于数组长度。如果索引大于或等于数组长度,Rust 会出现 *panic*。这种检查只能在运行时进行,比如在上面这种情况下,编译器无法在编译期知道用户运行代码时将输入什么值。
这种就是 Rust 的安全特性之一。在很多系统编程语言中,并不会检查数组越界问题,你会访问到无效的内存地址获取到一个风马牛不相及的值,最终导致在程序逻辑上出现大问题,而且这种问题会非常难以检查。
数组元素为非基础类型
学习了上面的知识,很多朋友肯定觉得已经学会了Rust的数组类型,但现实会给我们一记重锤,实际开发中还会碰到一种情况,就是数组元素是非基本类型的,这时候大家一定会这样写。
rust
let array = [String::from("rust is good!"); 8];
println!("{:#?}", array);然后你会惊喜的得到编译错误。
console
error[E0277]: the trait bound `String: std::marker::Copy` is not satisfied
--> src/main.rs:7:18
|
7 | let array = [String::from("rust is good!"); 8];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `std::marker::Copy` is not implemented for `String`
|
= note: the `Copy` trait is required because this value will be copied for each element of the array有些还没有看过特征的小伙伴,有可能不太明白这个报错,不过这个目前可以不提,我们就拿之前所学的所有权知识,就可以思考明白,前面几个例子都是Rust的基本类型,而基本类型在Rust中赋值是以Copy的形式,这时候你就懂了吧,let array=[3;5]底层就是不断的Copy出来的,但很可惜复杂类型都没有深拷贝,只能一个个创建。
接着就有小伙伴会这样写。
rust
let array = [String::from("rust is good!"),String::from("rust is good!"),String::from("rust is good!")];
println!("{:#?}", array);作为一个追求极致完美的Rust开发者,怎么能容忍上面这么难看的代码存在!
正确的写法,应该调用std::array::from_fn
rust
let array: [String; 8] = std::array::from_fn(|_i| String::from("rust is good!"));
println!("{:#?}", array);数组切片
在之前的章节,我们有讲到 切片 这个概念,它允许你引用集合中的部分连续片段,而不是整个集合,对于数组也是,数组切片允许我们引用数组的一部分:
rust
let a: [i32; 5] = [1, 2, 3, 4, 5];
let slice: &[i32] = &a[1..3];
assert_eq!(slice, &[2, 3]);上面的数组切片 slice 的类型是&[i32],与之对比,数组的类型是[i32;5],简单总结下切片的特点:
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
- 切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,
&str字符串切片也同理
总结
最后,让我们以一个综合性使用数组的例子,来结束本章节的学习:
rust
fn main() {
// 编译器自动推导出one的类型
let one = [1, 2, 3];
// 显式类型标注
let two: [u8; 3] = [1, 2, 3];
let blank1 = [0; 3];
let blank2: [u8; 3] = [0; 3];
// arrays是一个二维数组,其中每一个元素都是一个数组,元素类型是[u8; 3]
let arrays: [[u8; 3]; 4] = [one, two, blank1, blank2];
// 借用arrays的元素用作循环中
for a in &arrays {
print!("{:?}: ", a);
// 将a变成一个迭代器,用于循环
// 你也可以直接用for n in a {}来进行循环
for n in a.iter() {
print!("\t{} + 10 = {}", n, n+10);
}
let mut sum = 0;
// 0..a.len,是一个 Rust 的语法糖,其实就等于一个数组,元素是从0,1,2一直增加到到a.len-1
for i in 0..a.len() {
sum += a[i];
}
println!("\t({:?} = {})", a, sum);
}
}做个总结,数组虽然很简单,但是其实还是存在几个要注意的点:
- 数组类型容易跟数组切片混淆,[T;n]描述了一个数组的类型,而[T]描述了切片的类型, 因为切片是运行期的数据结构,它的长度无法在编译期得知,因此不能用[T;n]的形式去描述
[u8; 3]和[u8; 4]是不同的类型,数组的长度也是类型的一部分- 在实际开发中,使用最多的是数组切片[T],我们往往通过引用的方式去使用
&[T],因为后者有固定的类型大小
至此,关于数据类型部分,我们已经全部学完了。